最近在做一个学业规划小程序,涉及到的后端数据量有些大,这里谈一下数据库优化方面的内容
原始数据量以及SQL优化
首先需要存储所有的大学、大学下的学院,学院下的专业。大学的数据量为几百条,学院则为一万条左右,专业十几万条数据。
于是就有了一个查询语句:
SELECT *
FROM university u
JOIN college "c" ON u.id = c.university_id
JOIN major m on m.college_id = c.id很显然,想要数据库查询的速度变快,给ON条件相关列加上索引是必要的,因此在college和major的university_id和college_id上添加了BTree索引
但是查询结果如下:

效率并不高。
原因是使用了select * 导致了数据传输量的增加,且优化器为了返回大量数据可能进行的是全表扫描而非索引扫描,因此查询速度很慢。至于查询慢的原因后续再说明。
优化的方式很简单,指定查询列就行。于是得到了下面的sql
SELECT u.id as university_id, u.name as university_name,
c.id as college_id, c.name as college_name,
m.id as major_id, m.name as major_name
FROM university u
JOIN college "c" ON u.id = c.university_id
JOIN major m on m.college_id = c.id但是这个sql的查询效率依旧不理想
考虑到实际的分页查询一匹数据最多查询100条左右,这里模拟一下分页查询的条件
SELECT u.id as university_id, u.name as university_name,
c.id as college_id, c.name as college_name,
m.id as major_id, m.name as major_name
FROM university u
JOIN college "c" ON u.id = c.university_id
JOIN major m on m.college_id = c.id
limit 1000 offset 20000这个查询效率就非常迅速了

数据查询速度缓慢的分析
对于上面的sql,分别进行分析,只需要再SQL前加上 EXPLAIN ANALYZE 就行了
对于第一个,执行结果如下:
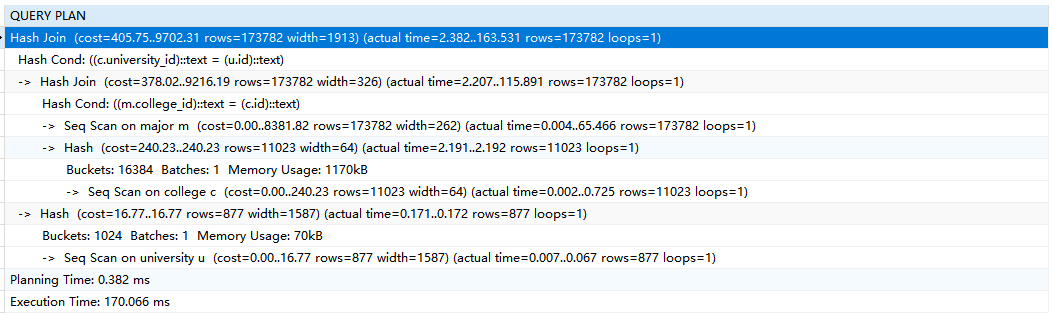
对于第二个,执行结果如下:
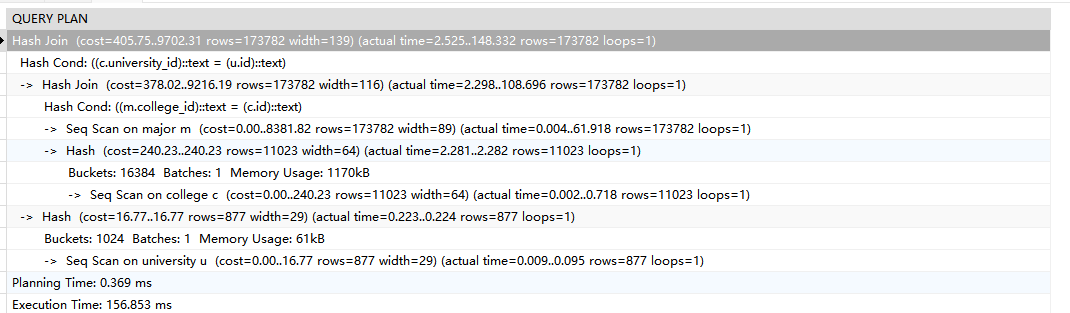
可以发现,第一个和第二个对major表的所有数据进行了两次HashJoin和一次全表扫描。因此查询效率应当是是一致的,之所以出现运行时间的查询,主要在于第一个SQL查询的列过多,在17万条记录中返回这些数据会导致IO操作和传输数据耗费了大部分时间。
第三个的执行结果如下:

和第二个相比,第三个的查询效率就高了很多,因为其HashJoin和扫描的数据量更少,且查询到的数据更少,因此更快速。
总结
索引不是万能的:大数据量下传输和处理的成本可能超过索引收益
分页是必须的:即使索引完美,也应避免全量数据返回
EXPLAIN是利器:性能分析必须依赖执行计划而非猜测



